Regression Analysis
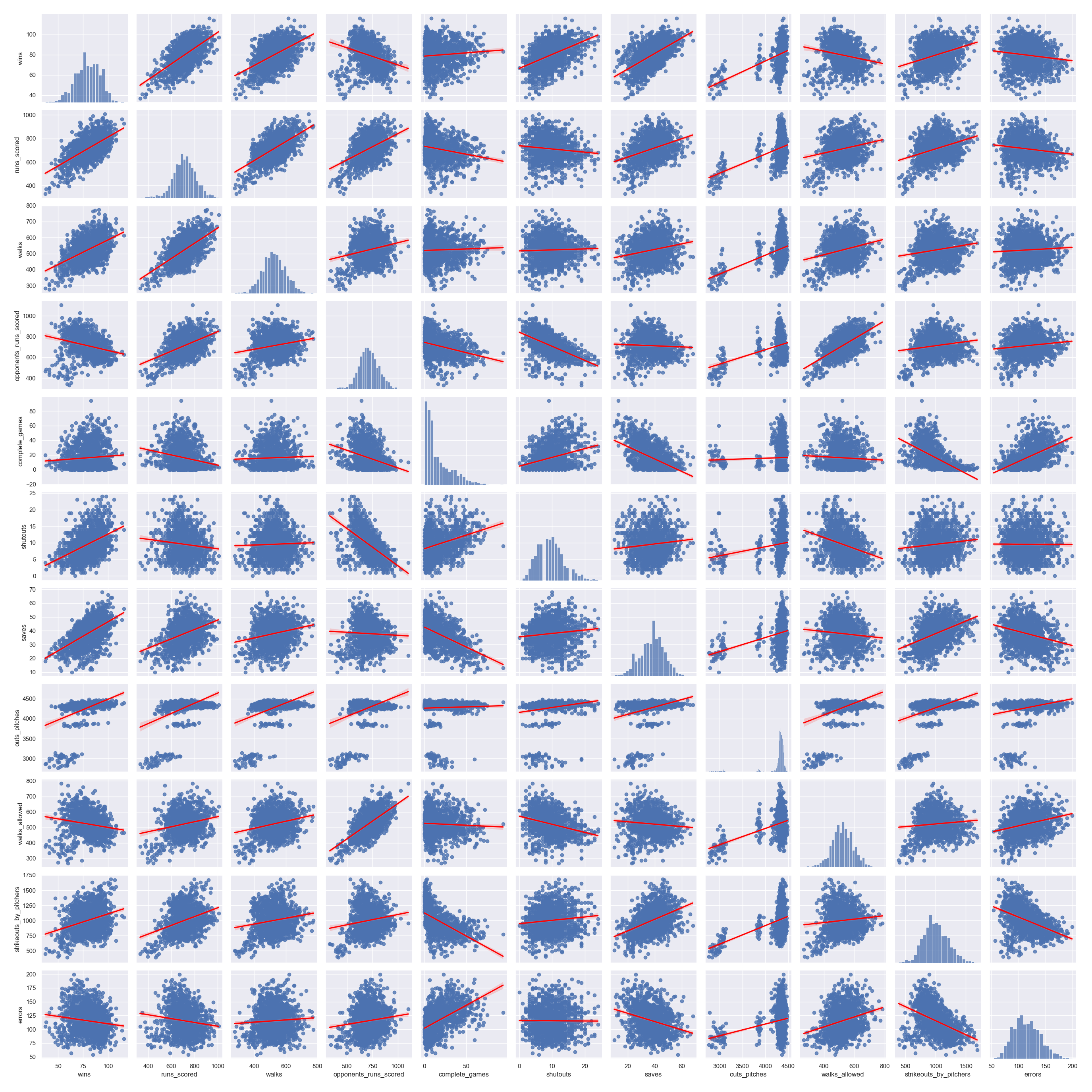
After initial data processing and cleaning, our dataset contained 1384 rows and 31 columns, corresponding to MLB stats from 1970 to 2019, including 36 teams, and the following metrics and variables:
| year | walks | saves |
| team_name | strikeouts_by_batters | outs_pitches |
| games_played | stolen_bases | hits_allowed |
| wins | caught_stealing | homeruns_allowed |
| losses | batters_hit_by_pitch | walks_allowed |
| runs_scored | sacrifice_flies | strikeouts_by_pitchers |
| hits | opponents_runs_scored | errors |
| doubles | earned_runs_allowed | double_plays |
| triples | complete_games | fielding_percentage |
| homeruns | shutouts | class' |
We wanted to understand how much of the variability in the response variable y (number of “wins”) can be explained by changes in an X number of variables.
Additionally, we wanted to find whether the number of variables can be reduced without affecting the model score significantly. Our approach was to perform
a Stepwise Regression Analysis, which is the iterative construction of a model where independent variables are removed in succession and testing for
statistical significance after each iteration (Kwok, 2021). This process is illustrated in the figure below.
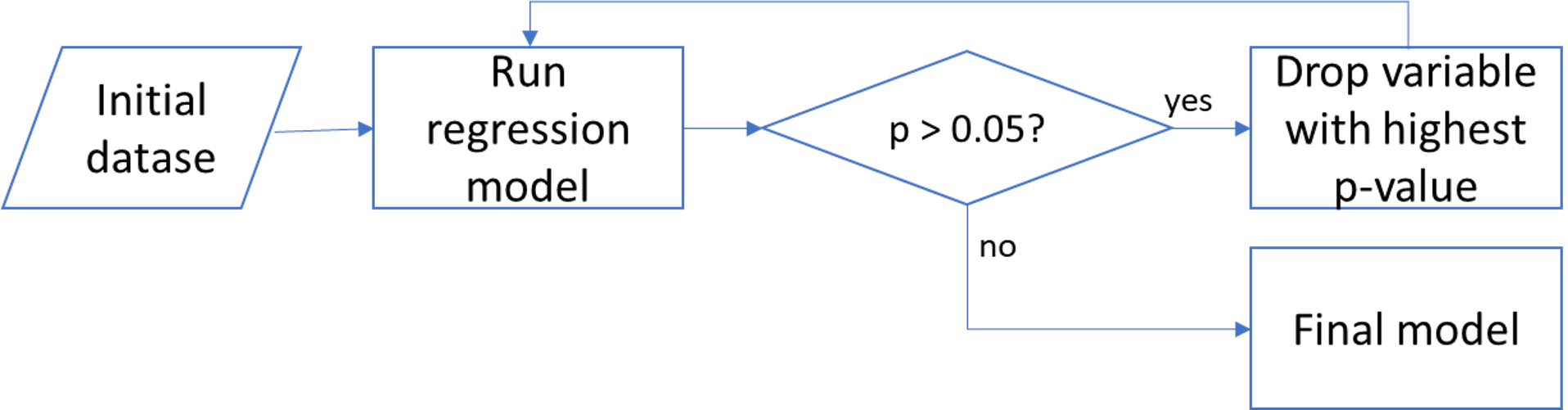
After this process, our final model contained 10 independent variables (down from 24). Furthermore, collinearity was tested using the Variance Inflation Factor,
and one additional variable was dropped. The final list of dependent variables are shown in the table below.
| runs_scored | saves |
| walks | outs_pitches |
| opponents_runs_scored | walks_allowed |
| complete_games | strikeouts_by_pitchers |
| shutouts | errors |
We also tested the model performance and the results are listed below:
- R2 Score: 0.9304714673783749
- Training Score: 0.9303466731994289
- Testing Score: 0.9297116942632093
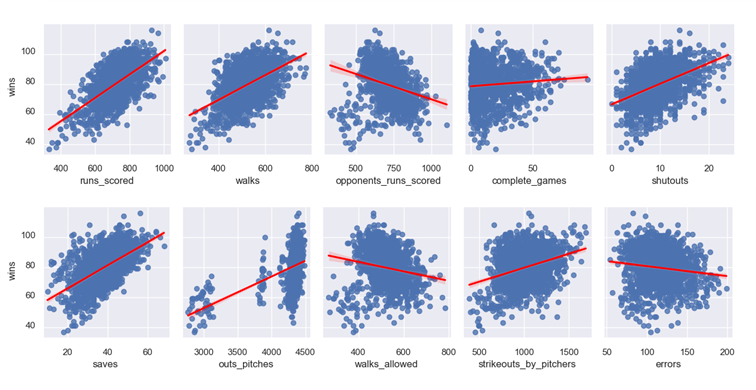
A pairplot was generated to visually explor how each independent variable correlated with the dependent variable ("wins"). The figure below shows the top row.
Kwok, Ryan. 2021. Stepwise Regression Tutorial in Python.